
大型语言模型 (LLM) 是推动生成式 AI 聊天机器人迅速崛起的基础技术。 ChatGPT、Google Bard 和 Bing Chat 等工具都依赖 LLM 来对您的提示和问题生成类似人类的响应。
但究竟什么是大型语言模型,它们是如何运作的? 在这里,大眼仔带您一起着手揭开大型语言模型的神秘面纱。
什么是大型语言模型?
用最简单的术语来说,大型语言模型是一个庞大的文本数据数据库,可以参考这些数据库来对您的提示生成类似人类的响应。 文本来自各种来源,可能达到数十亿字。
使用的文本数据的常见来源包括:
- 文学:大型语言模型通常包含大量的当代和古典文学。 这可以包括书籍、诗歌和戏剧。
- 在线内容:大型语言模型通常包含大量在线内容存储库,包括博客、网络内容、论坛问题和回复以及其他在线文本。
- 新闻和时事:一些(但不是全部)大型语言模型可以访问当前的新闻主题。 某些大型语言模型,如 GPT-3.5,在这个意义上受到限制。
- 社交媒体:社交媒体代表着巨大的自然语言资源。 大型语言模型数据使用来自常见的社交媒体等主要平台的文本。
当然,拥有庞大的文本数据库是一回事,但大型语言模型需要接受培训才能理解它,从而产生类似人类的反应。 它是如何做到这一点的是我们接下来要介绍的内容。
大型语言模型如何工作?
大型语言模型如何使用这些存储库来创建他们的响应? 第一步是使用称为深度学习的过程来分析数据。
深度学习用于识别人类语言的模式和细微差别。 这包括了解语法和句法。 但重要的是,它还包括上下文。 了解上下文是大型语言模型的重要组成部分。
让我们看一个大型语言模型如何使用上下文的示例。
下图中的提示提到晚上看到小狗。 由此,ChatGPT 了解到我们在谈论一种动物,而不是其它东西等。 当然,Bing Chat 或 Google Bard 等其他聊天机器人的回答可能完全不同。

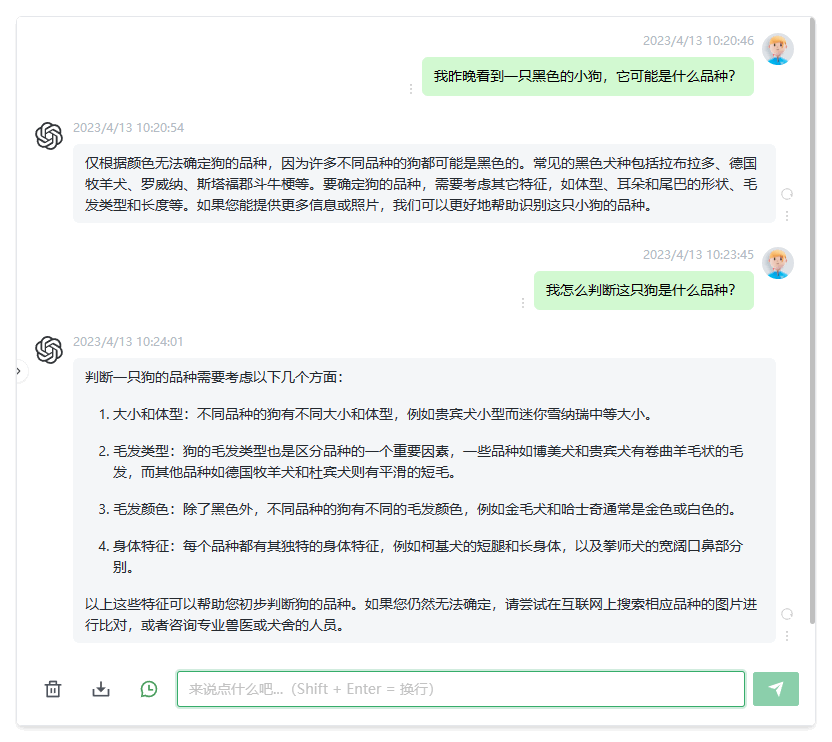 ChatGPT 大型语言模型
ChatGPT 大型语言模型
但是,它并非万无一失,正如本例所示,有时您需要提供额外的信息才能获得所需的响应。
为了生成这些响应,大型语言模型使用一种称为自然语言生成 (NLG) 的技术。 这涉及检查输入并使用从其数据存储库中学习的模式来生成上下文正确且相关的响应。
但是大型语言模型比这更深入。 他们还可以根据输入的情绪基调定制回复。 当与上下文理解相结合时,这两个方面是允许大型语言模型创建类似人类响应的主要驱动力。
总而言之,大型语言模型使用海量文本数据库,结合深度学习和 NLG 技术,为您的提示创建类似人类的响应。 但这可以实现的目标是有限的。
大型语言模型的局限性是什么?
大型语言模型代表了一项令人印象深刻的技术成就。 但这项技术远非完美,而且它们能实现的目标仍有很多限制。 下面列出了其中一些比较值得注意的:
- 上下文理解:我们提到这是大型语言模型将其纳入他们的答案的内容。 然而,他们并不总是正确的,而且往往无法理解上下文,导致不恰当或完全错误的答案。
- 偏差:训练数据中存在的任何偏差通常会出现在响应中。 这包括对性别、种族、地理和文化的偏见。
- 常识:常识很难量化,但人类从小就通过观察周围的世界来学习。 大型语言模型没有这种固有的经验可以依靠。 他们只了解通过他们的训练数据提供给他们的内容,而这并不能使他们真正理解他们所处的世界。
- 大型语言模型的好坏取决于它的训练数据:永远无法保证准确性。 “垃圾输入,垃圾输出”这句古老的计算机格言完美地总结了这个限制。 大型语言模型只有在其训练数据的质量和数量允许的情况下才能发挥作用。
还有一种观点认为,道德问题可以被视为大型语言模型的局限性,但这个主题不在本文的讨论范围之内。
3 个热门大型语言模型示例
人工智能的持续进步现在在很大程度上得到了大型语言模型的支持。 因此,虽然它们不完全是一项新技术,但它们肯定已经达到了临界点,并且现在有很多模型。
以下是一些使用最广泛的大型语言模型。
1. GPT
生成式预训练转换器 (GPT) 可能是最广为人知的大型语言模型。 GPT-3.5 为本文示例中使用的 ChatGPT 平台提供支持,而最新版本 GPT-4 可通过 ChatGPT Plus 订阅获得。 微软还在其 Bing Chat 平台中使用了最新版本。
2. LaMDA
这是 Google 的 AI 聊天机器人 Google Bard 使用的初始大型语言模型。 Bard 最初推出的版本被描述为大型语言模型的“精简版”。
3. BERT
BERT 代表来自 Transformers 的双向编码器表示。 该模型的双向特性将 BERT 与 GPT 等其他大型语言模型 区分开来。
已经开发了更多的大型语言模型,并且从主要的大型语言模型中很常见分支。 随着它们的发展,这些将在复杂性、准确性和相关性方面继续增长。 但是大型语言模型的未来会怎样?
大型语言模型的未来
这些无疑将塑造我们未来与技术互动的方式。 ChatGPT 和 Bing Chat 等模型的快速采用证明了这一事实。 短期内,人工智能不太可能取代你的工作。 但是,这些在未来将在我们的生活中扮演多大的角色仍然存在不确定性。
伦理争论可能对我们如何将这些工具融入社会有发言权。 然而,撇开这一点,一些预期的大型语言模型发展包括:
- 提高效率:大型语言模型具有数亿个参数,它们非常耗费资源。 随着硬件和算法的改进,它们可能会变得更加节能。 这也将加快响应时间。
- 提高情境意识:大型语言模型是自我训练的; 他们获得的使用和反馈越多,他们就会变得越好。 重要的是,这没有任何进一步的重大工程。 随着技术的进步,这将看到语言能力和上下文意识的改进。
- 针对特定任务进行培训:作为大型语言模型公开面孔的万能工具很容易出错。 但随着他们的发展和用户针对特定需求对他们进行培训,大型语言模型可以在医学、法律、金融和教育等领域发挥重要作用。
- 更大的整合:大型语言模型可以成为个人数字助理。 想想苹果的 Siri,你就明白了。 大型语言模型可以成为虚拟助手,帮助你处理从建议膳食到处理信件等一切事情。
这些只是大型语言模型可能成为我们生活方式的重要组成部分的几个领域。
大型语言模型转型和教育
大型语言模型正在开启一个充满可能性的激动人心的世界。 ChatGPT、Bing Chat 和 Google Bard 等聊天机器人的迅速崛起就是资源涌入该领域的证据。
如此丰富的资源只会让这些工具变得更加强大、通用和准确。 这些工具的潜在应用是巨大的,而目前,我们只是触及了新资源的表面。
文章名称:《什么是大型语言模型 (LLM) 以及它们如何工作?》
文章固定链接:http://www.dayanzai.me/what-are-large-langauge-models.html
本站资源仅供个人学习交流,请于下载后 24 小时内删除,不允许用于商业用途,否则法律问题自行承担。
-
 阅读更多
阅读更多如果您对PC游戏、加密货币、视频编辑或3D建模感兴趣,您可能需要一台配备高端显卡的PC。甚至人工智...
-
阅读更多
为什么 ChatGPT-4 比 ChatGPT-3.5 慢?
随着ChaGPT的最新版本GPT-4于2023年3月发布,许多人现在想知道为什么它与其前身GPT-3.5相比速度如...
猜你喜欢
- 2024-06-16什么是后端?前端开发者也需要了解的知识
- 2024-01-03优秀截图工具 Screenpresso Pro 2.1.22.0 中文多语免费版
- 2022-06-07Inno Setup 安装自动检测 .NET 环境安装解决方案
- 2024-07-08Windows 启动项管理工具 HiBit Startup Manager 2.6.45 中文多语免费版
- 2014-08-10皇家守卫军 2 – 边境 Flash 独立版 经典益智塔防游戏
相关推荐
- 2024-05-24开源媒体播放器 QMPlay2 Build 24.05.23 + x64 中文多语免费版
- 2024-04-12无线 WiFi 诊断工具 WirelessMon 5.0 Bulid 1002 中文免费版
- 2023-04-26Windows 系统预装卸载工具 O&O AppBuster 1.3.1343 中文汉化版
- 2019-03-21专业图标设计制作工具 ArtIcons Pro 5.52 中文多语免费版
- 2018-10-01微软 Mac Office 2019 中文版 Microsoft Office 2019 for Mac 16.17.0 Multi Language 下载


